NOKIA Separate Training Framework for AIML-based CSI Compression
NOKIA Separate Training Framework for AIML-based CSI Compression
Channel State Information (CSI) acquisition at the Base Station (BS) received from each User Equipment (UE) is critical to sweep its beam towards the corresponding UE accurately. However, transmitting uncompressed CSI in limited-rate feedback channels is impossible due to the significant signalling overhead in the uplink channel. This motivates us to exploit the potential of employing Artificial Intelligence/Machine Learning (AIML) for CSI compression and reconstruction. An AI encoder at UE has been investigated to compress and quantize the CSI to a codeword in bits before sending it over the air to the network (NW), which contains an AI decoder to reconstruct CSI. Conventionally, the AI encoder and decoder are trained jointly in the same training session. However, it enforces the disclosure of the proprietary AI encoder or AI decoder details among UE and NW vendors.
To address this issue, Nokia developed a separate training collaboration scheme [1] as part of the CENTRIC collaboration framework, which has gained support both from UE vendors and NW vendors in standardization fora. The proposed solution allows the UE-side CSI generation part and the network-side CSI reconstruction part to be trained separately by the UE side and network side, respectively. This is a user-CENTRIC version of the separate training scheme, providing flexibility regarding cell-site and scenario configuration-specific model support. The AI-based encoder and decoders have been trained using the Nokia Machine Learning Platform (NMLP).
Network-first separate training scheme with raw dataset sharing
The scheme we propose has two training phases, as shown in Figure 1.
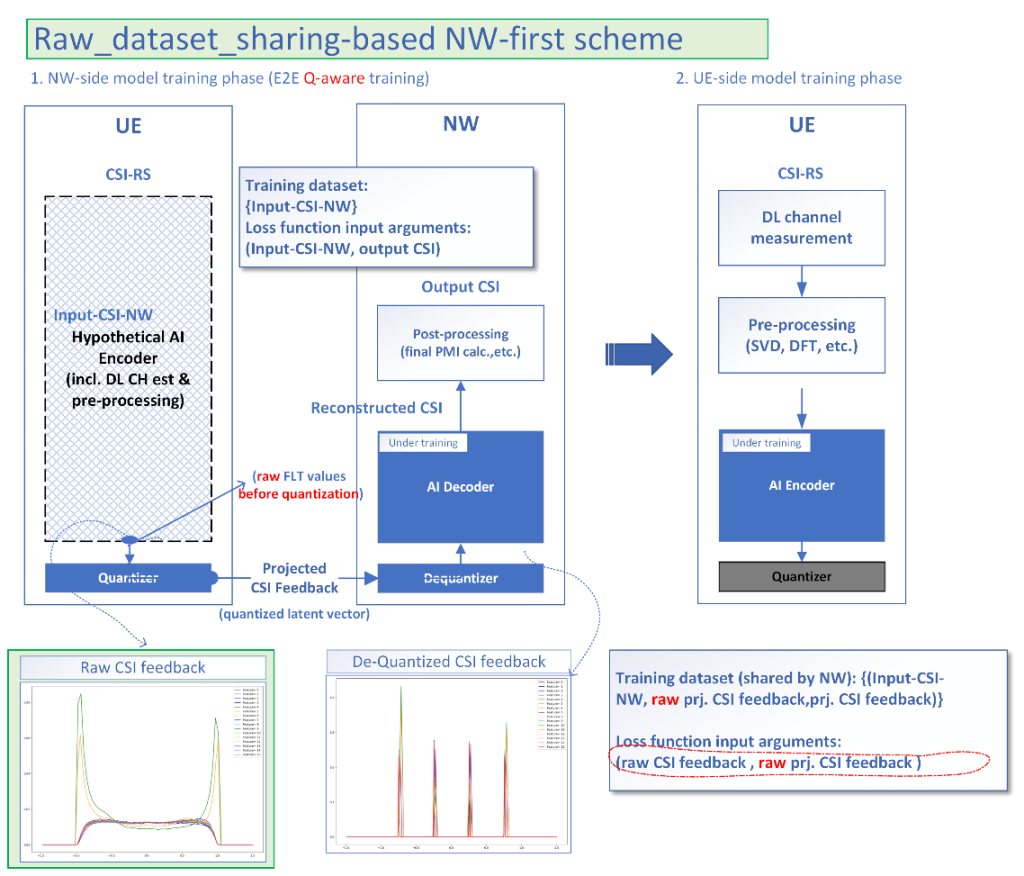
Figure 1. Training scheme for AIML-enabled CSI compression without sharing proprietary information among UE and NW vendors
During phase 1, the NW-side decoder model trains with a UE-side quantizer (Q) and a corresponding de-quantizer (dQ) at the NW-side. The proposed idea is agnostic to any specific quantization scheme, i.e., scalar quantization (SQ) or vector quantization (VQ). Note that the Q-dQ operation itself can be configured to be trained. The initial NW side decoder training is done in an end-to-end manner, assuming a specific type of encoder is employed at the UE side. In the next step, the trained encoder and decoder are put into inference mode to generate the training data to be shared with the UE vendors. The essence of our proposed scheme lies in the step of data generation for the second phase of the UE-side training. The conventional NW-first scheme proposes to share the “quantized projected CSI feedback´´. Unlike the conventional NW-first approach, we proposed to share the “raw projected CSI feedback´´. This step facilitates the accurate learning of the UE side encoder during the UE side training based on the raw projected CSI feedback.
In phase 2 of the training, the UE side encoder is trained on the raw data obtained from the previous step without any need of sharing proprietary AI decoder information. Optionally, a quantizer learning or a codebook generation (in the case of vector quantization) might be required. In the end, end-to-end model inference testing is done to evaluate the performance. Note that the proposed approach requires repetition for every CR (Compression Ratio) and quantization bit resolution combination to acquire trained parameter sets associated with each CR and bit resolution combination.
The proposed AIML-enabled CSI feedback scheme is plugged layer-wise inside the MU-MIMO system-level simulator with 210 UEs. The proposed separate training scheme (sepNWFirstwRawDS) is compared to the joint end-to-end (jointE2E) and conventional NW-first separate training (“sepNwFirst”) scheme in terms of mean uplink channel spectrum efficiency (SpEff), as shown in Figure 2.
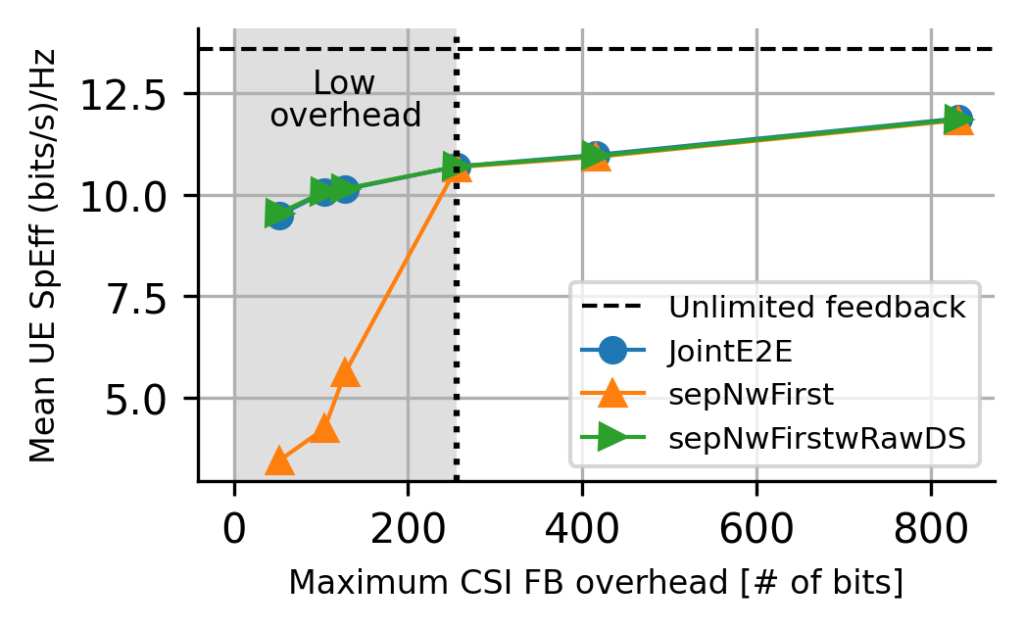
Figure 2. Mean uplink channel spectral efficiency for rank 2 as a function of required maximum overhead bits for ideal full channel eigenvector reconstruction (“Unlimited feedback”), the joint end-to-end (“JointE2E”), NW-first separate training (“sepNwFirst”), and the proposed NW-first separate training with raw dataset sharing (“sepNwFirstwRawDS”), respectively
The proposed separate training scheme performs significantly better than the conventional NW-first scheme, particularly in low-overhead regions. It should also be noted that the proposed scheme performs close to the joint end-to-end scheme. However, the proposed scheme provides a separate training framework for the UE-side encoder and the NW-side decoder without any additional requirement for sharing proprietary model information among UE and NW vendors.
The proposed separate training scheme performs significantly better than the conventional NW-first scheme, particularly in low-overhead regions. It should also be noted that the proposed scheme performs close to the joint end-to-end scheme. However, the proposed scheme provides a separate training framework for the UE-side encoder and the NW-side decoder without any additional requirement for sharing proprietary model information among UE and NW vendors.
Future Scope
As discussed, the proposed separate training framework performs close to the joint end-to-end training of the UE-side encoder and NW-side decoder, and this is without any need to share model proprietary information among UE and NW vendors. As in future work, this study can be extended to account for multiple encoder models on the UE side, thus mimicking a multi-vendor scenario. The problem of the model mismatch at the UE and NW-side is planned to be investigated.
[1] R1-2307238, “Evaluation of ML for CSI feedback enhancement”, Nokia, Nokia Shanghai Bell, 3GPP TSG RAN WG1 #114, August